9月8日,上海人工智能实验室(上海AI实验室)开源书生大模型 新一代训练引擎 XTuner V1。
XTuner V1 是伴随上海 AI 实验室“通专融合”技术路线的持续演进,以及书生大模型研发实践而成长起来的新一代训练引擎。相较于传统的 3D 并行训练引擎,XTuner V1 不仅能应对更加复杂的训练场景,还具备更快的训练速度,尤其在超大规模稀疏混合专家(MoE)模型训练中优势显著。
除了训练框架,书生大模型研发中使用的 AIOps 工具 DeepTrace 与 ClusterX 也将一并开源,为大规模分布式训练提供全方位保障。
目前开源社区主流的训练方案主要分为两类:
DeepSpeed / PyTorch FSDP(Fully Shard Data Parallel):通信量大但使用简单,尤其适合稠密型模型训练,开发者无需具备专业的 AI Infra 知识,也能开发出接近最优性能的训练系统;
3D 并行:通信量小但使用复杂,开发者需要具备专业的 AI Infra 知识,针对不同硬件和训练场景进行针对性调优,尤其适用 MoE 模型训练。
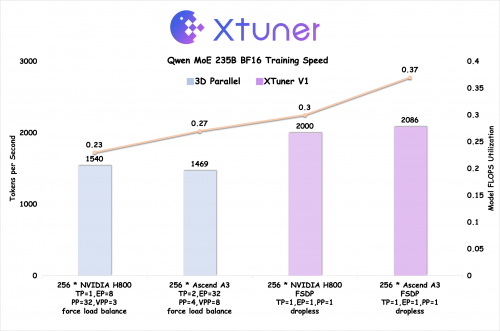
为了同时兼顾易用性、高性能与超大模型训练,XTuner V1 基于 PyTorch FSDP 进行开发,并针对 FSDP 通信量大的固有缺陷,进行了系列优化,可支持 1T 参数量级 MoE 模型训练,并首次在 200B 以上量级的混合专家模型上,实现训练吞吐超越传统的 3D 并行训练方案。
针对当前主流的 MoE 后训练需求,XTuner V1 未通过序列并行方式,实现200B 量级 MoE 模型单次 forward-backward 可处理 64k序列长度,更适合当下流行的强化学习训练场景;对专家并行依赖小,长序列训练时受专家不均衡影响小,200B 量级 MoE 无需专家并行,600B MoE 只需节点内专家并行,更适合现代 MoE Dropless 训练模式;大规模长短序列混训场景提速 2 倍以上,数据并行负载均衡,大幅减小因需序列长度不均衡导致的计算空泡。
同时,为了进一步挖掘 XTuner V1 训练方案的上限,研究团队与华为昇腾技术团队在 Ascend A3 NPU 超节点上进行联合优化,充分利用超节点硬件特性,实现了更高的 MFU(Model FLOPS Utilization,模型浮点运算利用率)。在理论算力落后 NVIDIA H800 近 20% 的情况下,最终实现训练吞吐超过 H800 近 5%,MFU 反超 20% 以上,该项研究成果技术报告也将于近期发布。
多维度技术优化,专为“超大模型”而生
XTuner V1 之所以能在超大模型训练中展现出卓越的性能,核心在于它在显存、通信、负载等多个维度进行了系统性优化。这些优化协同作用,不仅带来了性能的跨越式提升,还兼顾了易用性、通用性与扩展性。
显存优化
Pytorch FSDP 与 3D 并行最大的差异在于重计算。3D 并行时会尽可能减少重计算的占比,显存峰值主要来自于计算图中记录的激活值;Pytorch FSDP 则严重依赖于重计算,显存峰值主要来自于为重计算保留的激活值和模型最后计算损失函数时的计算图。
针对计算损失函数时的计算图,XTuner V1 基于 Liger-Kernel 中的 Chunk-wise Loss,扩展支持了更多种类的损失函数,能够支持 Ascend NPU;针对重计算保留的激活值,XTuner V1 借鉴了 MindSpeed 中的 Async Checkpointing Swap。
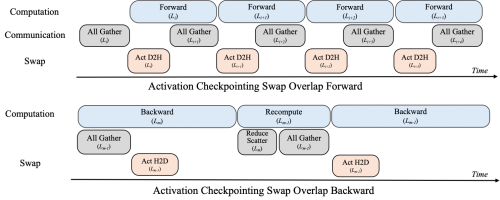
Async Checkpointing Swap 会在模型第 i 层前向计算开始时,将重计算需要保存的激活值从 Device 搬运到 Host,释放对应激活值占用的显存;在第 m 层反向传播时,会提前将第 m-1 层重计算需要的激活值从 Host 侧搬运回 Device 侧,反向传播结束时会自动释放对应的显存占用。
最终,无需借助序列并行技术,实现 200B 参数量级 MoE 模型训练 64K 长度序列。
通信掩盖
FSDP 会将参数均匀地切分在每张卡上,在模型的第 i 层计算时,会提前聚合第 i+1 层的参数,当第 i 层计算结束后,会将第 i 层的参数重新切分回每张卡上。这种模式极大地节省了模型参数占用的显存,但也增大了通信量,如果每层计算的耗时小于通信耗时,就会产生计算空泡,导致算力浪费。

得益于极致的显存优化,XTuner V1 可以让单次迭代的最大序列长度提升数倍,从而增加每层计算的耗时,掩盖参数聚合的通信耗时。

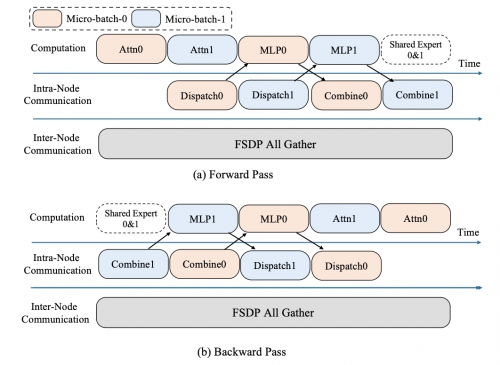
针对因显存或通信带宽受限,无法实现通信掩盖的训练场景,XTuner V1 通过 Intra-Node Domino-EP 来降低每一层聚合参数的通信量,同时掩盖因引入专家并行带来的额外通信开销。
DP 负载均衡
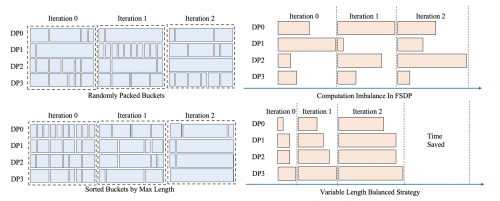
大模型训练时,通常会将多条句子拼接至一个固定长度,计算时使用变长注意力机制。32 个 1k 长度句子拼接得到的 32k 序列,计算耗时会远小于 2 个 16k 句子拼接得到的 32k 序列,数据并行维度越大,越容易出现计算空泡。
由于 XTuner V1 中没有引入 TP、PP 等并行策略,相同卡数下,数据并行的维度会远大于 3D 并行。为了缓解变长注意力带来的计算空泡,并尽可能不影响数据的训练顺序,会对每 n 个 step 内的已拼接好的序列进行排序,让每次计算时,不同 DP 的最长子序列长度是接近的。
基于昇腾超节点深度优化,理论算力落后情况下训练效率反超NVIDIA H800
为了进一步探究 XTuner V1 训练方案的上限,联合团队在 Ascend A3 NPU 超节点上进行了深度优化,充分利用超节点硬件特性,实现了更高的 MFU。在理论算力落后 NVIDIA H800 20% 的情况下,最终实现训练吞吐反超 H800 近 5%,MFU 反超 20% 以上。
昇腾超节点通过高速总线连接多颗NPU,突破互联瓶颈,让超节点像一台计算机一样工作,更加适合 FSDP 训练,相较于 NVIDIA H800,:
更高的通信带宽:最大可实现 384 颗 NPU 点到点超大带宽互联, FSDP All Gather 耗时仅为 H800 的 1/4~1/3,更容易实现计算-通信掩盖
计算通信解耦:通过专用硬化调度和传输卸载,实现不占用计算核的高效数据通信,FSDP 计算通信掩盖时不会影响计算速度
灵衢总线:CPU 和 NPU 通过灵衢总线互联,带宽远超PCIe,Checkpointing Swap 的开销更小
除硬件固有优势外,昇腾还从通信、内存、计算、框架、工具等维度对基于超节点的 MoE 训练进行了全方位的加持:
Cube调优:对于模型中集中了大量计算任务的GroupedMatmul算子进行分析,发现内部搬运带宽已经拥塞但cube利用率还有提升空间。针对此问题,联合研发团队重点优化GroupedMatmul算子分块逻辑,根据不同输入进行动态分块Tiling策略优化搬运效率。同时,根据场景的不同细化Cache策略,提高Cache命中率从而提升性能。
QoS调优:QoS(Quality of Service)即服务质量。在有限的带宽资源下,QoS为各种业务分配带宽,为业务提供端到端的服务质量保证。大规模训练过程中,计算流、通信流、swap 流都会存在HBM带宽访问,并发的访问会导致HBM带宽拥塞,从而影响整体性能。通过适当调低通信的HBM访存优先级,可以减少计算的搬运时间,从而优化端到端性能。
跨流内存复用:在 FSDP 计算流和通信流异步重叠的场景中,Ascend Extension for PyTorch(PTA)中默认的跨流内存优化会导致显存不能及时释放,需要开启 PTA 中进阶版的跨流内存复用机制(MULTI_STREAM_MEMORY_REUSE=2),可以显著降低显存峰值
集群性能工具高效诊断:借助 MindStudio 全流程工具链中的 msprof-analyze 性能分析工具与 MindStudio Insight 可视化工具,开发者可以充分利用其强大的数据分析与可视化能力,在分钟级时间内精准识别 训练过程中的“快慢卡”现象根因,快速定位出性能瓶颈,显著提升大集群调优效率。
书生大模型工具链研发团队现已将Xtuner V1 的工作全部开源,希望为学术界与工业界提供高性能、低门槛、易扩展的大模型训练方案,丰富开源社区的训练工具生态,为超大模型研发和应用提供坚实易用的基础设施。
未来,在研究范式创新及模型能力提升的基础上,上海AI实验室将持续推进书生大模型及其全链条工具体系的开源,支持免费商用,同时提供线上开放服务,与各界共同拥抱更广阔的开源生态,共促大模型产业繁荣。





 央视融媒:京公网安备 11010502039440号
央视融媒:京公网安备 11010502039440号
